
clean-fid0.1.35
Published
FID calculation in PyTorch with proper image resizing and quantization steps
pip install clean-fid
Package Downloads
Authors
Project URLs
Requires Python
clean-fid for Evaluating Generative Models

Project | Paper |
Colab-FID |
Colab-Resize |
Leaderboard Tables
Quick start: Calculate FID | Calculate KID
[New] Computing the FID using CLIP features [Kynkäänniemi et al, 2022] is now supported. See here for more details.
The FID calculation involves many steps that can produce inconsistencies in the final metric. As shown below, different implementations use different low-level image quantization and resizing functions, the latter of which are often implemented incorrectly.
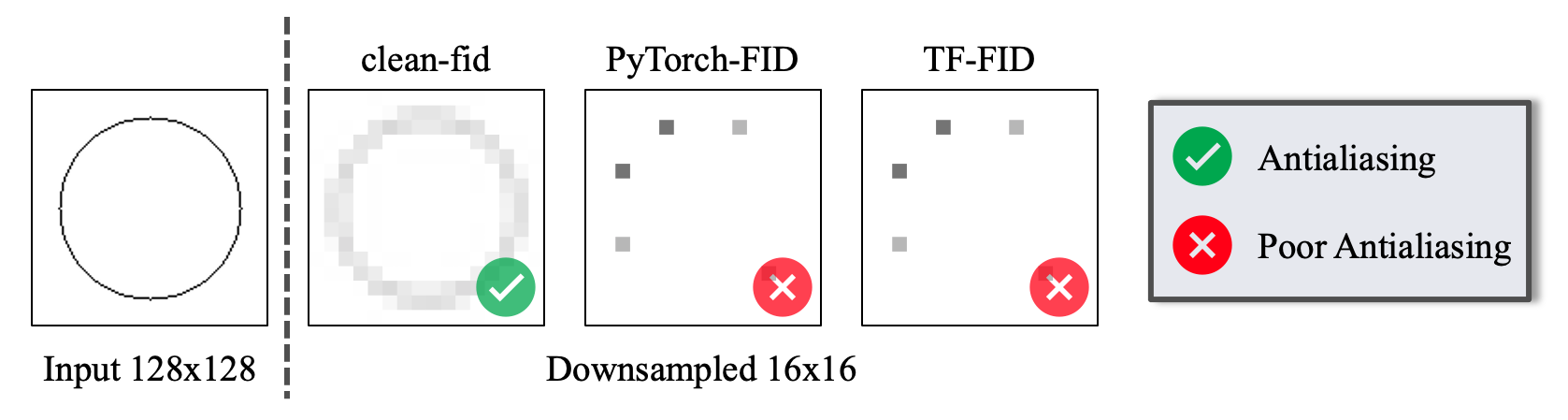
We provide an easy-to-use library to address the above issues and make the FID scores comparable across different methods, papers, and groups.
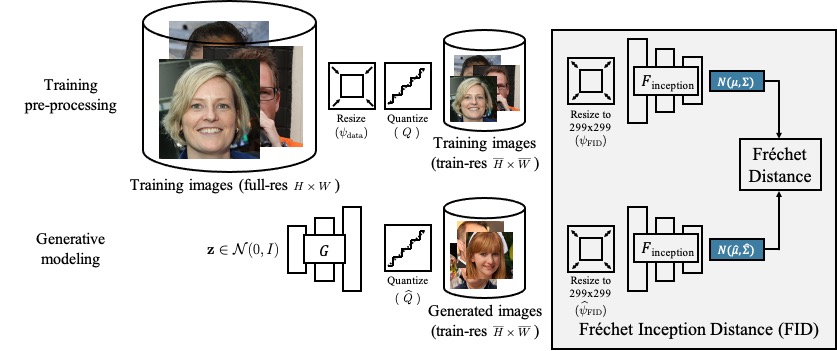
Corresponding Manuscript
On Aliased Resizing and Surprising Subtleties in GAN Evaluation
Gaurav Parmar, Richard Zhang, Jun-Yan Zhu
CVPR, 2022
CMU and Adobe
If you find this repository useful for your research, please cite the following work.
@inproceedings{parmar2021cleanfid,
title={On Aliased Resizing and Surprising Subtleties in GAN Evaluation},
author={Parmar, Gaurav and Zhang, Richard and Zhu, Jun-Yan},
booktitle={CVPR},
year={2022}
}
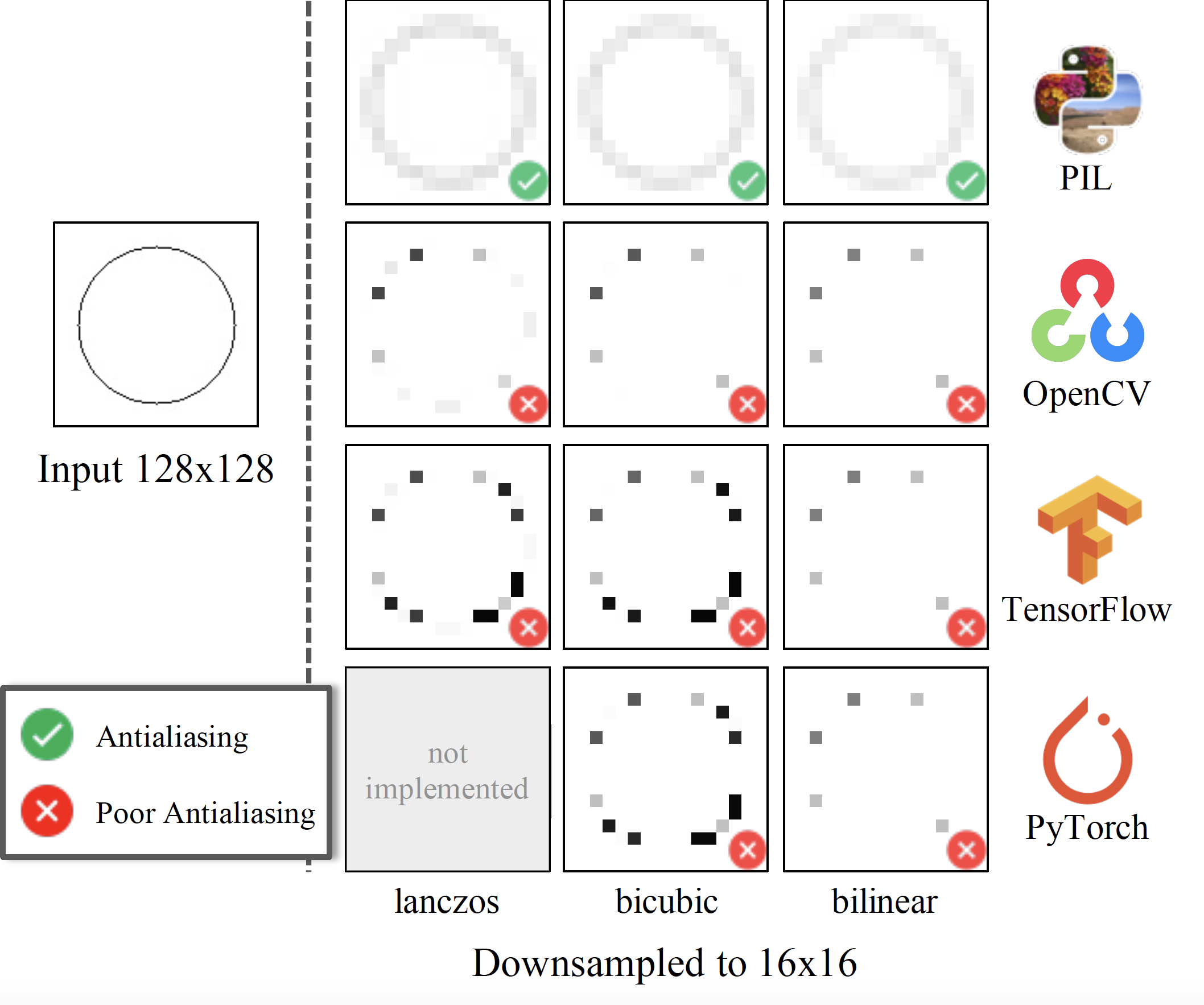
Aliased Resizing Operations
The definitions of resizing functions are mathematical and should never be a function of the library being used. Unfortunately, implementations differ across commonly-used libraries. They are often implemented incorrectly by popular libraries. Try out the different resizing implementations in the Google colab notebook here.
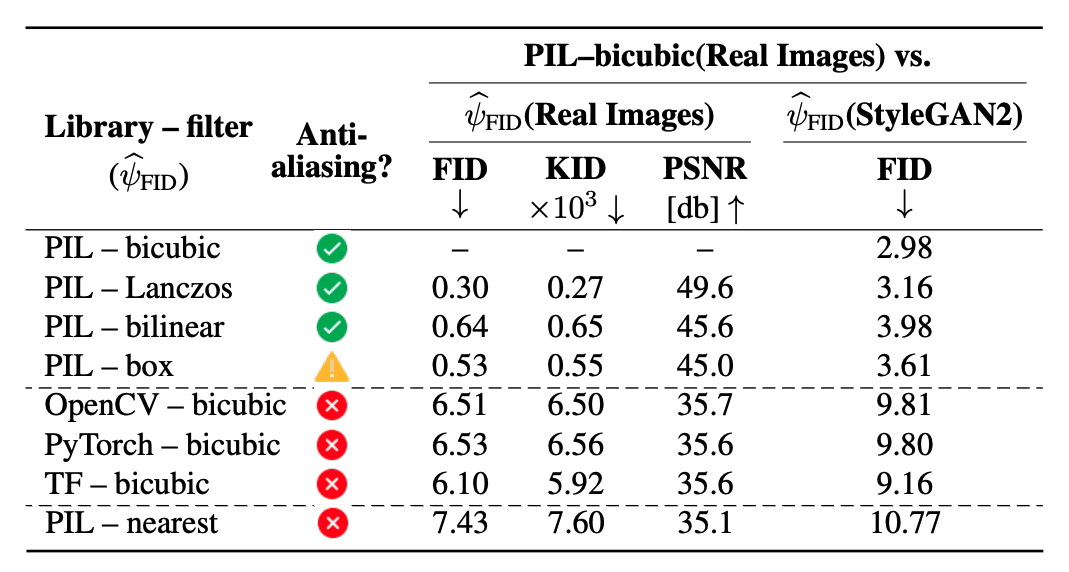
The inconsistencies among implementations can have a drastic effect of the evaluations metrics. The table below shows that FFHQ dataset images resized with bicubic implementation from other libraries (OpenCV, PyTorch, TensorFlow, OpenCV) have a large FID score (≥ 6) when compared to the same images resized with the correctly implemented PIL-bicubic filter. Other correctly implemented filters from PIL (Lanczos, bilinear, box) all result in relatively smaller FID score (≤ 0.75). Note that since TF 2.0, the new flag antialias (default: False) can produce results close to PIL. However, it was not used in the existing TF-FID repo and set as False by default.
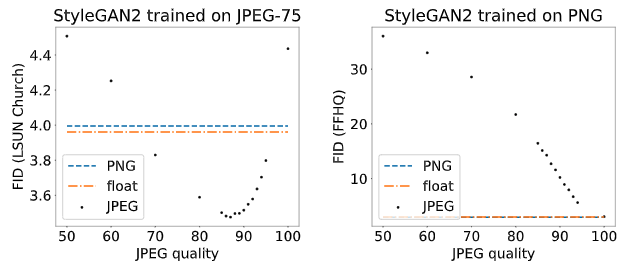
JPEG Image Compression
Image compression can have a surprisingly large effect on FID. Images are perceptually indistinguishable from each other but have a large FID score. The FID scores under the images are calculated between all FFHQ images saved using the corresponding JPEG format and the PNG format.

Below, we study the effect of JPEG compression for StyleGAN2 models trained on the FFHQ dataset (left) and LSUN outdoor Church dataset (right). Note that LSUN dataset images were collected with JPEG compression (quality 75), whereas FFHQ images were collected as PNG. Interestingly, for LSUN dataset, the best FID score (3.48) is obtained when the generated images are compressed with JPEG quality 87.
Quick Start
- install the library
pip install clean-fid
Computing FID
- Compute FID between two image folders
from cleanfid import fid score = fid.compute_fid(fdir1, fdir2) - Compute FID between one folder of images and pre-computed datasets statistics (e.g.,
FFHQ)from cleanfid import fid score = fid.compute_fid(fdir1, dataset_name="FFHQ", dataset_res=1024, dataset_split="trainval70k") - Compute FID using a generative model and pre-computed dataset statistics:
from cleanfid import fid # function that accepts a latent and returns an image in range[0,255] gen = lambda z: GAN(latent=z, ... , <other_flags>) score = fid.compute_fid(gen=gen, dataset_name="FFHQ", dataset_res=256, num_gen=50_000, dataset_split="trainval70k")
Computing CLIP-FID
To use the CLIP features when computing the FID [Kynkäänniemi et al, 2022], specify the flag model_name="clip_vit_b_32"
- e.g. to compute the CLIP-FID between two folders of images use the following commands.
from cleanfid import fid score = fid.compute_fid(fdir1, fdir2, mode="clean", model_name="clip_vit_b_32")
Computing KID
The KID score can be computed using a similar interface as FID.
The dataset statistics for KID are only precomputed for smaller datasets AFHQ, BreCaHAD, and MetFaces.
- Compute KID between two image folders
from cleanfid import fid score = fid.compute_kid(fdir1, fdir2) - Compute KID between one folder of images and pre-computed datasets statistics
from cleanfid import fid score = fid.compute_kid(fdir1, dataset_name="brecahad", dataset_res=512, dataset_split="train") - Compute KID using a generative model and pre-computed dataset statistics:
from cleanfid import fid # function that accepts a latent and returns an image in range[0,255] gen = lambda z: GAN(latent=z, ... , <other_flags>) score = fid.compute_kid(gen=gen, dataset_name="brecahad", dataset_res=512, num_gen=50_000, dataset_split="train")
Supported Precomputed Datasets
We provide precompute statistics for the following commonly used configurations. Please contact us if you want to add statistics for your new datasets.
| Task | Dataset | Resolution | Reference Split | # Reference Images | mode |
|---|---|---|---|---|---|
| Image Generation | cifar10 | 32 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | cifar10 | 32 | test | 10,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | ffhq | 1024, 256 | trainval | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | ffhq | 1024, 256 | trainval70k | 70,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_church | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_church | 256 | trainfull | 126,227 | clean |
| Image Generation | lsun_horse | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_horse | 256 | trainfull | 2,000,340 | clean |
| Image Generation | lsun_cat | 256 | train | 50,000 | clean, legacy_tensorflow, legacy_pytorch |
| Image Generation | lsun_cat | 256 | trainfull | 1,657,264 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_cat | 512 | train | 5153 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_dog | 512 | train | 4739 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | afhq_wild | 512 | train | 4738 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | brecahad | 512 | train | 1944 | clean, legacy_tensorflow, legacy_pytorch |
| Few Shot Generation | metfaces | 1024 | train | 1336 | clean, legacy_tensorflow, legacy_pytorch |
| Image to Image | horse2zebra | 256 | test | 140 | clean, legacy_tensorflow, legacy_pytorch |
| Image to Image | cat2dog | 256 | test | 500 | clean, legacy_tensorflow, legacy_pytorch |
Using precomputed statistics In order to compute the FID score with the precomputed dataset statistics, use the corresponding options. For instance, to compute the clean-fid score on generated 256x256 FFHQ images use the command:
fid_score = fid.compute_fid(fdir1, dataset_name="ffhq", dataset_res=256, mode="clean", dataset_split="trainval70k")
Create Custom Dataset Statistics
-
dataset_path: folder where the dataset images are stored
-
custom_name: name to be used for the statistics
-
Generating custom statistics (saved to local cache)
from cleanfid import fid fid.make_custom_stats(custom_name, dataset_path, mode="clean") -
Using the generated custom statistics
from cleanfid import fid score = fid.compute_fid("folder_fake", dataset_name=custom_name, mode="clean", dataset_split="custom") -
Removing the custom stats
from cleanfid import fid fid.remove_custom_stats(custom_name, mode="clean") -
Check if a custom statistic already exists
from cleanfid import fid fid.test_stats_exists(custom_name, mode)
Backwards Compatibility
We provide two flags to reproduce the legacy FID score.
-
mode="legacy_pytorch"
This flag is equivalent to using the popular PyTorch FID implementation provided here
The difference between using clean-fid with this option and code is ~2e-06
See doc for how the methods are compared -
mode="legacy_tensorflow"
This flag is equivalent to using the official implementation of FID released by the authors.
The difference between using clean-fid with this option and code is ~2e-05
See doc for detailed steps for how the methods are compared
Building clean-fid locally from source
python setup.py bdist_wheel
pip install dist/*
CleanFID Leaderboard for common tasks
We compute the FID scores using the corresponding methods used in the original papers and using the Clean-FID proposed here. All values are computed using 10 evaluation runs. We provide an API to query the results shown in the tables below directly from the pip package.
If you would like to add new numbers and models to our leaderboard, feel free to contact us.
CIFAR-10 (few shot)
The test set is used as the reference distribution and compared to 10k generated images.
100% data (unconditional)
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 (+ada + tuning) [Karras et al, 2020] | - † | - † | 8.20 ± 0.10 |
| stylegan2 (+ada) [Karras et al, 2020] | - † | - † | 9.26 ± 0.06 |
| stylegan2 (diff-augment) [Zhao et al, 2020] [ckpt] | 9.89 | 9.90 ± 0.09 | 10.85 ± 0.10 |
| stylegan2 (mirror-flips) [Karras et al, 2020] [ckpt] | 11.07 | 11.07 ± 0.10 | 12.96 ± 0.07 |
| stylegan2 (without-flips) [Karras et al, 2020] | - † | - † | 14.53 ± 0.13 |
| AutoGAN (config A) [Gong et al, 2019] | - † | - † | 21.18 ± 0.12 |
| AutoGAN (config B) [Gong et al, 2019] | - † | - † | 22.46 ± 0.15 |
| AutoGAN (config C) [Gong et al, 2019] | - † | - † | 23.62 ± 0.30 |
† These methods use the training set as the reference distribution and compare to 50k generated images
20% data
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 12.15 | 12.12 ± 0.15 | 14.18 ± 0.13 |
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 23.08 | 23.01 ± 0.19 | 29.49 ± 0.17 |
10% data
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 14.50 | 14.53 ± 0.12 | 16.98 ± 0.18 |
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 36.02 | 35.94 ± 0.17 | 43.60 ± 0.17 |
CIFAR-100 (few shot)
The test set is used as the reference distribution and compared to 10k generated images.
100% data
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 16.54 | 16.44 ± 0.19 | 18.44 ± 0.24 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 15.22 | 15.15 ± 0.13 | 16.80 ± 0.13 |
20% data
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 32.30 | 32.26 ± 0.19 | 34.88 ± 0.14 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 16.65 | 16.74 ± 0.10 | 18.49 ± 0.08 |
10% data
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 45.87 | 45.97 ± 0.20 | 46.77 ± 0.19 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 20.75 | 20.69 ± 0.12 | 23.40 ± 0.09 |
FFHQ
all images @ 1024x1024
Values are computed using 50k generated images
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID | Reference Split |
|---|---|---|---|---|
| stylegan1 (config A) [Karras et al, 2020] | 4.4 | 4.39 ± 0.03 | 4.77 ± 0.03 | trainval |
| stylegan2 (config B) [Karras et al, 2020] | 4.39 | 4.43 ± 0.03 | 4.89 ± 0.03 | trainval |
| stylegan2 (config C) [Karras et al, 2020] | 4.38 | 4.40 ± 0.02 | 4.79 ± 0.02 | trainval |
| stylegan2 (config D) [Karras et al, 2020] | 4.34 | 4.34 ± 0.02 | 4.78 ± 0.03 | trainval |
| stylegan2 (config E) [Karras et al, 2020] | 3.31 | 3.33 ± 0.02 | 3.79 ± 0.02 | trainval |
| stylegan2 (config F) [Karras et al, 2020] [ckpt] | 2.84 | 2.83 +- 0.03 | 3.06 +- 0.02 | trainval |
| stylegan2 [Karras et al, 2020] [ckpt] | N/A | 2.76 ± 0.03 | 2.98 ± 0.03 | trainval70k |
140k - images @ 256x256 (entire training set with horizontal flips)
The 70k images from trainval70k set is used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| zCR [Zhao et al, 2020] † | 3.45 ± 0.19 | 3.29 ± 0.01 | 3.40 ± 0.01 |
| stylegan2 [Karras et al, 2020] † | 3.66 ± 0.10 | 3.57 ± 0.03 | 3.73 ± 0.03 |
| PA-GAN [Zhang and Khoreva et al, 2019] † | 3.78 ± 0.06 | 3.67 ± 0.03 | 3.81 ± 0.03 |
| stylegan2-ada [Karras et al, 2020] † | 3.88 ± 0.13 | 3.84 ± 0.02 | 3.93 ± 0.02 |
| Auxiliary rotation [Chen et al, 2019] † | 4.16 ± 0.05 | 4.10 ± 0.02 | 4.29 ± 0.03 |
| Adaptive Dropout [Karras et al, 2020] † | 4.16 ± 0.05 | 4.09 ± 0.02 | 4.20 ± 0.02 |
| Spectral Norm [Miyato et al, 2018] † | 4.60 ± 0.19 | 4.43 ± 0.02 | 4.65 ± 0.02 |
| WGAN-GP [Gulrajani et al, 2017] † | 6.54 ± 0.37 | 6.19 ± 0.03 | 6.62 ± 0.03 |
† reported by [Karras et al, 2020]
30k - images @ 256x256 (Few Shot Generation)
The 70k images from trainval70k set is used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 6.16 | 6.14 ± 0.064 | 6.49 ± 0.068 |
| DiffAugment-stylegan2 [Zhao et al, 2020] [ckpt] | 5.05 | 5.07 ± 0.030 | 5.18 ± 0.032 |
10k - images @ 256x256 (Few Shot Generation)
The 70k images from trainval70k set is used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 14.75 | 14.88 ± 0.070 | 16.04 ± 0.078 |
| DiffAugment-stylegan2 [Zhao et al, 2020] [ckpt] | 7.86 | 7.82 ± 0.045 | 8.12 ± 0.044 |
5k - images @ 256x256 (Few Shot Generation)
The 70k images from trainval70k set is used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 26.60 | 26.64 ± 0.086 | 28.17 ± 0.090 |
| DiffAugment-stylegan2 [Zhao et al, 2020] [ckpt] | 10.45 | 10.45 ± 0.047 | 10.99 ± 0.050 |
1k - images @ 256x256 (Few Shot Generation)
The 70k images from trainval70k set is used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 62.16 | 62.14 ± 0.108 | 64.17 ± 0.113 |
| DiffAugment-stylegan2 [Zhao et al, 2020] [ckpt] | 25.66 | 25.60 ± 0.071 | 27.26 ± 0.077 |
LSUN Categories
100% data
The 50k images from train set is used as the reference images and compared to 50k generated images.
| Category | Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|---|
| Outdoor Churches | stylegan2 [Karras et al, 2020] [ckpt] | 3.86 | 3.87 ± 0.029 | 4.08 ± 0.028 |
| Horses | stylegan2 [Karras et al, 2020] [ckpt] | 3.43 | 3.41 ± 0.021 | 3.62 ± 0.023 |
| Cat | stylegan2 [Karras et al, 2020] [ckpt] | 6.93 | 7.02 ± 0.039 | 7.47 ± 0.035 |
LSUN CAT - 30k images (Few Shot Generation)
All 1,657,264 images from trainfull split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 10.12 | 10.15 ± 0.04 | 10.87 ± 0.04 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 9.68 | 9.70 ± 0.07 | 10.25 ± 0.07 |
LSUN CAT - 10k images (Few Shot Generation)
All 1,657,264 images from trainfull split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 17.93 | 17.98 ± 0.09 | 18.71 ± 0.09 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 12.07 | 12.04 ± 0.08 | 12.53 ± 0.08 |
LSUN CAT - 5k images (Few Shot Generation)
All 1,657,264 images from trainfull split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 34.69 | 34.66 ± 0.12 | 35.85 ± 0.12 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 16.11 | 16.11 ± 0.09 | 16.79 ± 0.09 |
LSUN CAT - 1k images (Few Shot Generation)
All 1,657,264 images from trainfull split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2-mirror-flips [Karras et al, 2020] [ckpt] | 182.85 | 182.80 ± 0.21 | 185.86 ± 0.21 |
| stylegan2-diff-augment [Zhao et al, 2020] [ckpt] | 42.26 | 42.07 ± 0.16 | 43.12 ± 0.16 |
AFHQ (Few Shot Generation)
AFHQ Dog
All 4739 images from train split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 19.37 | 19.34 ± 0.08 | 20.10 ± 0.08 |
| stylegan2-ada [Karras et al, 2020] [ckpt] | 7.40 | 7.41 ± 0.02 | 7.61 ± 0.02 |
AFHQ Wild
All 4738 images from train split are used as the reference images and compared to 50k generated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 3.48 | 3.55 ± 0.03 | 3.66 ± 0.02 |
| stylegan2-ada [Karras et al, 2020] [ckpt] | 3.05 | 3.01 ± 0.02 | 3.03 ± 0.02 |
BreCaHAD (Few Shot Generation)
All 1944 images from train split are used as the reference images and compared to 50k generated images.
| Model | Legacy FID (reported) | Legacy FID (reproduced) | Clean-FID | Legacy KID (reported) 10^3 | Legacy KID (reproduced) 10^3 | Clean KID 10^3 |
|---|---|---|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 97.72 | 97.46 ± 0.17 | 98.35 ± 0.17 | 89.76 | 89.90 ± 0.31 | 92.51 ± 0.32 |
| stylegan2-ada [Karras et al, 2020] [ckpt] | 15.71 | 15.70 ± 0.06 | 15.63 ± 0.06 | 2.88 | 2.93 ± 0.08 | 3.08 ± 0.08 |
MetFaces (Few Shot Generation)
All 1336 images from train split are used as the reference images and compared to 50k generated images.
| Model | Legacy FID (reported) | Legacy FID (reproduced) | Clean-FID | Legacy KID (reported) 10^3 | Legacy KID (reproduced) 10^3 | Clean KID 10^3 |
|---|---|---|---|---|---|---|
| stylegan2 [Karras et al, 2020] [ckpt] | 57.26 | 57.36 ± 0.10 | 65.74 ± 0.11 | 35.66 | 35.69 ± 0.16 | 40.90 ± 0.14 |
| stylegan2-ada [Karras et al, 2020] [ckpt] | 18.22 | 18.18 ± 0.03 | 19.60 ± 0.03 | 2.41 | 2.38 ± 0.05 | 2.86 ± 0.04 |
Horse2Zebra (Image to Image Translation)
All 140 images from test split are used as the reference images and compared to 120 translated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| CUT [Park et al, 2020] | 45.5 | 45.51 | 43.71 |
| Distance [Benaim and Wolf et al, 2017] reported by [Park et al, 2020] | 72.0 | 71.97 | 71.01 |
| FastCUT [Park et al, 2020] | 73.4 | 73.38 | 72.53 |
| CycleGAN [Zhu et al, 2017] reported by [Park et al, 2020] | 77.2 | 77.20 | 75.17 |
| SelfDistance [Benaim and Wolf et al, 2017] reported by [Park et al, 2020] | 80.8 | 80.78 | 79.28 |
| GCGAN [Fu et al, 2019] reported by [Park et al, 2020] | 86.7 | 85.86 | 83.65 |
| MUNIT [Huang et al, 2018] reported by [Park et al, 2020] | 133.8 | - † | 120.48 |
| DRIT [Lee et al, 2017] reported by [Park et al, 2020] | 140.0 | - † | 99.56 |
† The translated images for these methods were intitially compared by [Park et al, 2020] using .jpeg compression. We retrain these two methods using the same protocal and generate the images as .png for a fair comparision.
Cat2Dog (Image to Image Translation)
All 500 images from test split are used as the reference images and compared to 500 translated images.
| Model | Legacy-FID (reported) | Legacy-FID (reproduced) | Clean-FID |
|---|---|---|---|
| CUT [Park et al, 2020] | 76.2 | 76.21 | 77.58 |
| FastCUT [Park et al, 2020] | 94.0 | 93.95 | 95.37 |
| GCGAN [Fu et al, 2019] reported by [Park et al, 2020] | 96.6 | 96.61 | 96.49 |
| MUNIT [Huang et al, 2018] reported by [Park et al, 2020] | 104.4 | - † | 123.73 |
| DRIT [Lee et al, 2017] reported by [Park et al, 2020] | 123.4 | - † | 127.21 |
| SelfDistance [Benaim and Wolf et al, 2017] reported by [Park et al, 2020] | 144.4 | 144.42 | 147.23 |
| Distance [Benaim and Wolf et al, 2017] reported by [Park et al, 2020] | 155.3 | 155.34 | 158.39 |
† The translated images for these methods were intitially compared by [Park et al, 2020] using .jpeg compression. We retrain these two methods using the same protocal and generate the images as .png for a fair comparision.
Related Projects
torch-fidelity: High-fidelity performance metrics for generative models in PyTorch.
TTUR: Two time-scale update rule for training GANs.
LPIPS: Perceptual Similarity Metric and Dataset.
Licenses
All material in this repository is made available under the MIT License.
inception_pytorch.py is derived from the PyTorch implementation of FID provided by Maximilian Seitzer. These files were originally shared under the Apache 2.0 License.
inception-2015-12-05.pt is a torchscript model of the pre-trained Inception-v3 network by Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. The network was originally shared under Apache 2.0 license on the TensorFlow Models repository. The torchscript wrapper is provided by Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila which is released under the Nvidia Source Code License.